
Executive Summary
- Entro Labs researchers developed a hybrid secret-scanning pipeline that pairs a rules engine (regular expressions and heuristics) with a context-aware small language model (SLM).
- The pipeline is already live in enterprise customer environments, extending coverage beyond code to logs, configurations, and conversations for end-to-end visibility.
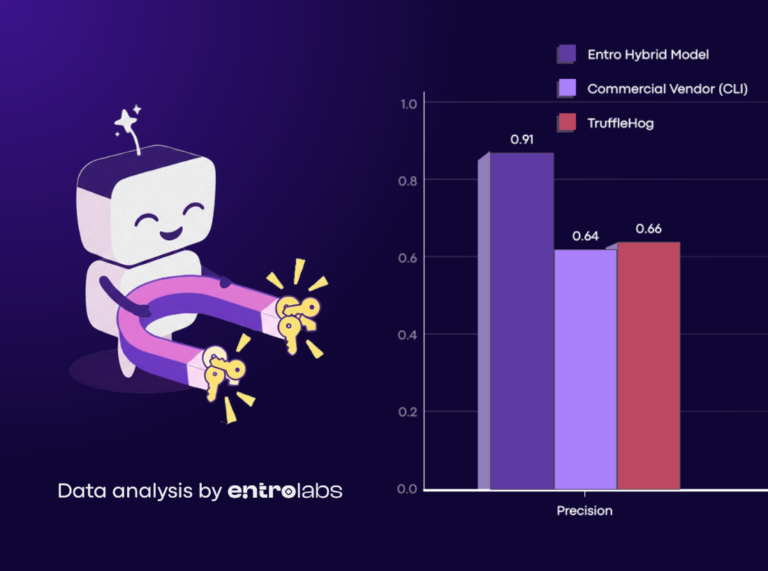
- On a 300-sample real-world benchmark, our hybrid approach achieved an F1 score of 0.91, effectively solving the precision-recall trade-off and turning a research concept into a resilient, production-grade system.
What Entro’s Hybrid Secret-Scanning Pipeline Is?
Today, most secret-detection scanners still rely heavily on regular expressions (regex) and hardcoded rules. The trade-off is simple: regex can match patterns, but it cannot understand context. So it often flags look-alike strings that are not actually secrets.
For example, a rules-based scanner will likely alert on this sample:
// LoginServiceTest.java
@Test
void testInvalidCredentialsThrowsException() {
assertThrows(AuthException.class, () ->
loginService.authenticate("admin", "P@ssw0rd123!")
);
}A human reader will immediately recognize that this is a test fixture. But for a rule-based engine, it is simply impossible to detect each and every scenario individually. The result may lead to a high false positive (FP) rate, alert fatigue, and constant rule maintenance as formats evolve. In our research, rule-based scanning caught only ~60% of potential leaks while still producing a high false positive rate (more on this in the Benchmark section).
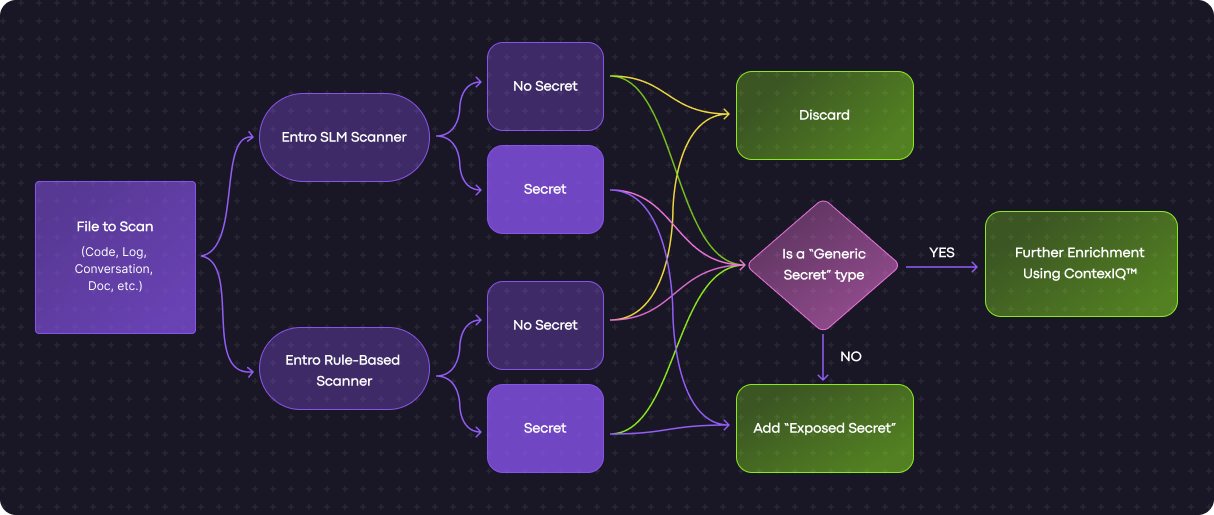
At Entro Labs, we developed a hybrid secret-scanning pipeline that combines a traditional rule-based discovery engine with state-of-the-art (SOTA) fine-tuned small language models (SLMs).
In production, finding secrets in source code is only the starting point for an effective, robust secret security solution. Entro Security also developed an advanced in-house validation layer, ContextIQ™, that performs deeper contextual checks and risk-aware validation. ContextIQ™ main goal is to reduce false positives further, validate the secrets state, and enrich the context before it surfaces to users (we’ll cover ContextIQ™ in a follow-up write-up).
The main subject of this article is the first step – reliably scanning secret candidates at scale.
The “Hybrid” approach shines in two main ways:
- The SLM instruction-tuning process (fine-tuning)
- The rule-based scanner generates the raw training signal by finding large numbers of candidate secrets at scale. We then curate those candidates into high-quality PEFT training examples for the SLM.
- Production: two signals, one decision
The SLM and the rules-based engine scan side by side and cross-check each other. This effectively helped improve secrets discovery by:- Lower the false negative (FN) rate: if one misses, the other can catch it.
- Lower the false positive (FP) rate: for ambiguous cases (e.g., generic strings and passwords), we require stronger agreement before triggering an alert.
- Continual improvement: disagreements become new training data that help close gaps over time.
Small Language Models (SLMs) – A Maturing Technology
SLMs vs. LLMs: what’s the difference that matters?
Small Language Models (SLMs) are the “little siblings” of LLMs (Large Language Models). They use the same core ideas, most commonly Transformer-based architectures with Attention Mechanisms (the magic that gives the model context-awareness). The difference is not the “type” of model, it’s the deployment and operating profile.
Here’s the practical split:
- LLMs are primarily designed for broad, general-purpose capabilities across many domains. That usually means larger model sizes, heavier compute, and more operational complexity (in general, LLM size spans over 8B params)
- SLMs are usually built for focused competence: instead of being good at a large range of tasks, they’re trained to be really good at a small number of well-defined jobs. That focus means faster inference, lower cost, and a setup that’s simpler to deploy, maintain, and iterate on. And because the system is smaller and more contained, it’s easier to secure and govern in production.
The shift toward SLMs is not just about model size. It’s about deployment advantages that matter in security pipelines: smaller models can run closer to the workload (on-device, on-prem, or inside a VPC), which helps keep sensitive data inside your boundary, cuts network and queue latency for high-throughput scanning, and improves unit economics when agents or scanners make many model calls per task.
That combination (privacy boundary, low latency, predictable cost) is exactly why SLMs are a good fit for secret scanning at scale.
SLMs in 2026
2026 is shaping up to be the year we’ll see many more SLMs pushed into production systems. The trend is simple: smaller models keep closing capability gaps while being easier to deploy, cheaper to run, and fast enough to sit directly inside high-throughput pipelines.
This isn’t just our take, either. A recent NVIDIA paper by Belcak et al. makes a similar point: as agents become more common, most model calls are small, repetitive, and task-specific, so it often makes more sense to run an SLM-first (or hybrid) stack, using LLMs only when you need their extensive general capabilities.
But there’s an important caveat: SLMs still come with real engineering challenges.
SLMs fine-tune require domain knowledge, careful dataset design, and a deep understanding of failure scenarios.
That’s exactly why Entro Security invested heavily in being ready for rapid iteration. Models and tools are released continuously, and every jump in architecture or training technique can change what “good data” looks like and how you fine-tune the model:
- Data collection: what we log, how we label, and even which examples matter can differ across model families and fine-tune techniques.
- Fine-tune: we constantly evaluate new fine-tuning methods (LoRA, QLoRA, DoRA, rsLoRA & FourierFT) and recipes to improve stability and task alignment.
- Production: we track advances in quantization, packing, and serving, using mature inference stacks (e.g., vLLM, TensorRT-LLM & SGLang) to improve throughput and reduce serving costs.
The SLM ecosystem is moving too fast for a “set and forget” approach. If you want SLMs to work in production, you need a pipeline that can quickly absorb new models, fine-tune techniques, and serving methods without sacrificing reliability and time.
In-house Secret-Scanner SLM
Building a secret-scanning SLM doesn’t mean “pick an open model, run PEFT/Fine-tuning, ship.” The fine-tuning step is rarely the hard part. Most of the work is in collecting high-quality training data, transforming and enriching it for fine-tuning, and iterating quickly.
In addition to secret scanning in production, our scanners are also used to collect training data. We run them at scale across open-source (OS) repositories and web-crawled code to harvest high-confidence candidate secret spans, producing hundreds of thousands of high-signal snippets for fine-tuning. This beats training on random text, and it’s where the hybrid approach starts paying off.
We also review real customer workloads and shape the dataset to match what we actually see in production. SLM for secret scanning is sensitive to data distribution. A model that performs well on curated examples can fall apart in noisy, real-world environments.
Finally, we build for fast, production-grade iteration. The SLM ecosystem changes weekly, so we developed a pipeline that can accommodate new base models, fine-tuning methods, and serving setups without making reliability a coin flip. And because this is a scanner (not a chatbot), we judge the models the same way production does: quality (relevant metrics such as Precision and Recall), throughput (the models’ ability to handle varying workloads), and strict output format. The goal isn’t the “smartest” model. The goal is to build the model with the lowest cost-per-file while remaining predictable under real-world load.
The Production Paradox
Another challenge when dealing with SLMs (and AI models in general) is serving them in production. SLMs tend to perform great in demos, but serving them to real customers is a different story: latency and budgets are tight, edge cases are constant, and a single bad prediction can cause real disruption. The higher the stakes of the task, the more you should plan for model failures and build safeguards around it.
That’s why resiliency is a first-class requirement for us: safe defaults, clear failure modes, and graceful degradation. If the SLM times out, returns unexpected output, or isn’t confident, we fall back to the rule-based scanner to prevent coverage from collapsing.
This production mindset also shapes the SLM training objective. We optimize for a machine-actionable signal and maximum security. This mindset led us to develop a model that finds potential secrets while keeping sensitive data in place – validating secrets without extracting or reprinting them, which reduces data exposure and helps mitigate the risk of secrets leaking from the model.
It’s All About Data
Data Preparation: Teaching the Model Context, Not Patterns
Before training, we analyzed customer workloads and then shaped the dataset to match those distributions: file lengths, file types (code, logs, docs, conversations), the ratio of files with secrets vs. without, the number of secrets per sample, and the mix of sources (open-source, synthetic, and proprietary).
Data ETL (Extraction, Transformation, and Loading) is a key part of fine-tuning an LLM or SLM for a downstream task.
The rule-based scanner played a main role in our SLM training: it served as our data engine. We ran it at scale on open-source repositories and crawled web pages to harvest a large pool of candidate secret spans. That bootstrap step gave us hundreds of thousands of “suspicious” snippets and other high-signal examples that reflect real-world environments. It’s important to note that we anonymized the samples to prevent leaked secrets from open-source code from entering the training set.
Filtering
We intentionally filtered out “pattern-only” examples (mainly certificates and RSA private keys) and extremely short snippets. The goal is to train the model to recognize secrets using the context around them. We didn’t want to train yet another regex engine in disguise. We kept only samples with enough surrounding context (lines around usage, configuration structure, comments, and intent) so the model learns why something is a secret.
Deduplication
Next came deduplication at scale. Open source is full of forks and templates, so we removed verbatim and near-verbatim snippets using MinHash-LSH (we shingled the text using the SLM tokenizer tokens). We also categorized semantically similar contexts (to improve context-based diversity) using embeddings: we generated embedding vectors with OpenAI’s text-embedding-3-small model, indexed them in FAISS, and retrieved approximate nearest neighbors via cosine similarity (implemented as the inner product over L2-normalized vectors).
Context Enrichment Via Claude Opus 4.5 and Google Gemini 3 Pro
For candidates that still lack sufficient surrounding context, we enriched them synthetically. We used a frontier LLM with varying temperatures (a sampling parameter that increases output diversity) to generate realistic, diverse surrounding code while keeping the original candidate region intact. This yielded a diverse dataset, which forces the SLM adapters to focus on complex patterns. Patterns that the model needs to handle in production environments: long, messy, real-world files, and not curated snippets.
LLM-as-Judge for Data Labeling
Finally, we labeled every candidate file using Claude Opus 4.5. For each sample, Claude classified every suspected secret in the file and attached a confidence and severity score. This lets us exclude public, fake, or placeholder values from the training positives while still retaining them as hard negatives. We then cross-checked Claude Opus 4.5’s verdicts against additional LLMs using an LLM-as-a-judge setup to reduce labeling errors and improve consistency.
Example classification output:
{
"file_has_secrets": true,
"secrets": [
{
"line": 69,
"type": "slack_webhook_url",
"value": "https://ho…q88",
"severity": "medium",
"confidence": "high"
}
]
}Data Characteristics
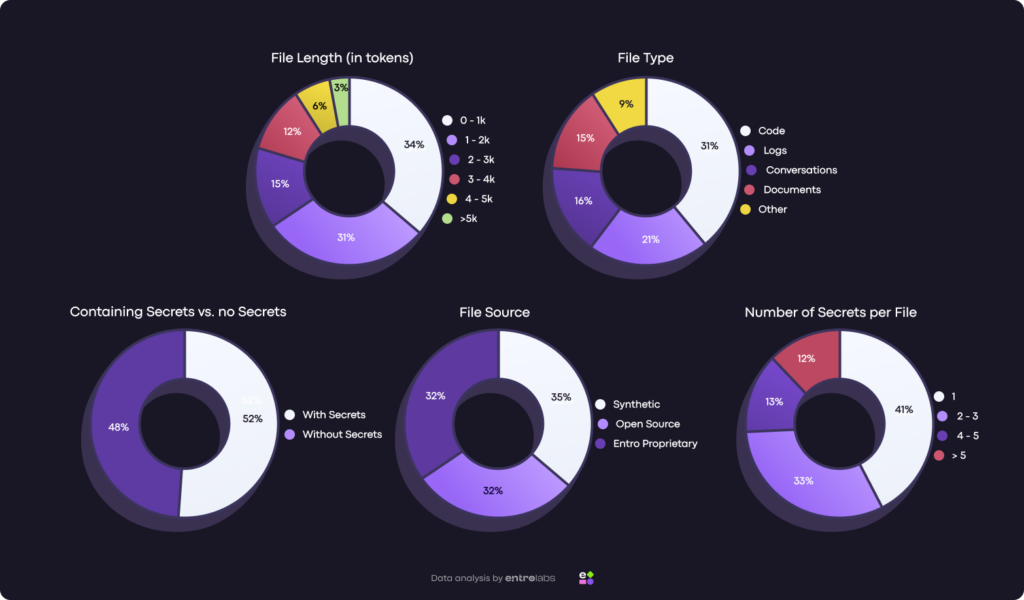
We ended up with what we actually wanted for PEFT: about 7K high-quality, high-diversity training examples. Small by design, but engineered to match production. Instead of maximizing volume, we maximized signal: each sample is context-rich, de-duplicated, and representative of real customer workloads. The result was a dataset that trains the SLM to make stable, machine-actionable decisions under the same messy distributions it will face in real-world environments.
Base Model Architecture and PEFT Process
Base Model Architecture
Our objective wasn’t to find the “smartest” general assistant. It was to select a base model that, after fine-tuning, would be a production-grade model capable of behaving like a reliable pipeline component with high, predictable throughput, stable instruction-following, and strong performance on messy, real-world data.
Model size was a hard constraint. We needed something small enough for fast inference and low serving cost, but robust enough to handle long contexts and ambiguous strings (for example, passwords and generic tokens).
State-of-the-Art (SOTA) SLMs we benchmarked
We reviewed a range of SOTA SLMs released over the past two years and narrowed the list down to three top candidates:
Ministral 3 3B
The latest model in the Ministral 3 family (released in Dec 2025). It delivered a strong overall performance and followed instructions reliably. The main limitation we encountered was robustness at scale: it struggled more with long-context inputs and with files containing more than ~5 secrets.
Llama 3.2 (1B / 3B)

These were among the first models we tested. The Llama 3.2 family has the best ecosystem support across common wrappers and training pipelines, and it strikes a solid balance between latency, throughput, and accuracy. That said, while the models performed well across the board, they did not clearly lead on any single dimension in our evaluation.

We tested Qwen3-4B, a dense model in the Qwen3 lineup. The standout advantage is context length: the default context window is 256K tokens, and some configurations extend higher up to 1M tokens, which is useful when scanning very large files. Overall, it performs well on most scan types and delivers strong, compatible performance compared to Llama 3.2.
Reasoning-Optimized vs. Instruction-Tuned Models
Reasoning or “thinking” models usually score higher than instruction-tuned models on many tasks. When a model can “reason” through messy inputs, it can improve performance on edge cases and complex files.
That said, while reasoning models have clear advantages over non-thinking models, we still used instruct models for production secret scanning, mainly because reasoning-style inference introduces two practical limitations:
- Latency – Reasoning-oriented models tend to generate additional tokens during processing. That overhead can be substantial, especially when scanning long files, and it noticeably increases end-to-end latency in responses compared to instruction-tuned models.
- Structured outputs – Secret scanning depends on a clean, predictable JSON response that could be parsed reliably into downstream signals. “Thinking” models tend to be less consistent on strictly structured output formats, since they’re optimized for general reasoning and explanation rather than tight, machine-readable, and constrained schemas.
PEFT (Parameter-Efficient Fine-Tuning)
The next step was to get an SLM to behave like a production-ready secret scanner: follow a strict JSON output format and consistent decisions over long, messy files.
We used Parameter-Efficient Fine-Tuning (PEFT) technique with rsLoRA, Rank-Stabilized LoRA (stabilization method for higher-rank LoRA adapters). This lets us specialize the model without the cost of full fine-tuning, and without the risk of wiping out its general capabilities and instruction-following behavior, a neural-network phenomenon called catastrophic forgetting.
Why LoRA fits secret scanning
Low-Rank Adaptation or LoRA adds small trainable “adapter” matrices to selected layers instead of updating the full model. In our setup, we applied LoRA across the self-attention and MLP layers.
- It adapts the model to a narrow task (secret scanning) while preserving most of the base model’s capabilities (instruction following, logical reasoning, text comprehension, mathematics, science, coding, and tool usage).
- It is faster and requires far less data than full fine-tuning (a few hundred/thousands of data samples, compared to millions when pre-training).
- It supports multiple task-specific adapters on the same base model. A neat feature that lets you plug several adapters into one model, enabling specialized capabilities.
We also tested this modularity to reduce cognitive load by splitting the scan workflow into separate LoRA adapters (scanning, extracting, and validating).
Secret scanning is full of “looks like a secret, but isn’t” cases. LoRA gave us enough flexibility to teach those context cues without retraining the entire model.
Rank mattered, so we went high.
LoRA rank (marked as r) is the dimension of the low-rank adapter matrices that approximate the weight update, and it effectively sets the adapter capacity. Higher ranks can model more complex changes (often with higher quality) but increase trainable parameters, memory, and compute roughly linearly with r. After trying multiple configurations, our best settings were r=64 and r = 128.
Higher ranks improved performance on hard cases: distinguishing tests from production, docs from live configs, placeholders from real tokens, and similar edge cases.
As shown in Figure 3, validation loss decreases with increasing rank. Ranks 64 and 128 converge to the lowest loss, with 128 slightly best overall.

Keeping high-rank training stable with rsLoRA
Higher ranks can get unstable. We used rsLoRA to keep updates well-behaved as rank increases, by adjusting the scaling of the LoRA update. This noticeably improved training stability at r = 64 and r = 128.
Training setup: long context, efficient iteration
Inputs can be very long, and the relevant context isn’t always near the secret-like string. To support long-context fine-tuning without runaway cost, we trained with very large context windows utilizing:
- NVIDIA A100 (40GB): a cost-effective, mid-tier training GPU that’s a great fit for our use case thanks to its relatively large 40GB of VRAM, which helps support long-context fine-tuning.
- Unsloth (https://unsloth.ai/docs): an Open-source library that hat wraps Hugging Face Transformers and improves training efficiency. In our setup it enabled:
- Longer context training (Unsloth reports up to ~153K context for specific configurations, compared to ~12K in a baseline HF setup for the referenced model). https://github.com/unslothai/unsloth?tab=readme-ov-file#llama-31-8b-max-context-length
- Faster training with lower VRAM usage (Unsloth reports up to ~2× speed and ~70% less VRAM, depending on configuration).
This setup kept iteration fast instead of turning training into an infrastructure project.
Prompt crafting
Prompt design has a big impact on performance and instruction-following, especially because we expected the model to scan very long files and behave reliably in long-context settings. That creates two practical challenges:
- Instruction retention: the model must keep following the task even when the relevant content is buried deep in the input.
- Output stability: it must return the same JSON schema every time, without drifting, adding fields, or “getting creative” as context grows.
One recurring failure mode we encountered was the “Lost in the Middle” effect: with long inputs, models tend to pay less attention to core instructions and can struggle to use information buried in the middle of the context. To address this, we adjusted the prompt to reduce cognitive load during inference, for example, by adding an instruction reminder at the end of the user prompt. We also used shorter, tighter instructions, a simpler output contract, and an input structure that keeps the task and constraints visible even when the context is very large.
Evaluation metrics
We evaluated the fine-tuned models using F1 score, and selected the configuration with the best F1.
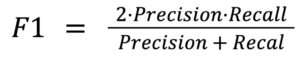
- Precision: of everything the scanner flagged, how many were actually real secrets (high precision means fewer false positives and less alert fatigue).
- Recall: of all real secrets present, how many the scanner successfully caught (high recall means fewer missed leaks).
- F1 score (harmonic mean): a single number that balances precision and recall. It only goes up when both improve.
F1 is well-suited for secret scanning because it captures the real trade-off: you want to catch real leaks and avoid noisy alerts. Unlike accuracy (percent correct overall), F1 isn’t inflated by the many “no-secret” cases and better reflects production behavior.
Benchmark
For the benchmark, we curated 300 code-only samples sourced from real open-source repositories. All files were anonymized to prevent exposure of real credentials while preserving the original structure and context.
To evaluate both precision and recall, we balanced the set, so about 51% of files contain one or more secrets while ~49% contain none.
Success criteria: exact secret extraction
We evaluated all models against a strict dual objective: the model must correctly identify both the secret value and its corresponding line number.
This distinction is critical. In secret scanning, merely flagging a line as “suspicious” is not enough. The real engineering challenge is exact boundary detection: identifying precisely where a secret begins and ends. This is especially hard for SLMs when dealing with long credentials, secrets embedded in URLs, or complex Base64 strings.
To mitigate the computational load and hallucination risks associated with text generation, we optimized the task to minimize the number of output tokens and reduce cognitive model load.
Rather than asking the model to reproduce the surrounding context, we focused the inference strictly on identifying the correct start and end locations. This reduces output “noise” and forces the model to prioritize extraction accuracy.
Secret scanners under test
We have benchmarked five leading open-source scanners:
- Trufflehog: the open source version of the Trufflehog scanner that discovers and classifies leaked credentials (like API keys, tokens, passwords, and private keys) across sources such as Git repos, filesystems, and cloud storage. It can also verify many detected secrets by testing them against the relevant service APIs, helping prioritize real, active exposures over false positives.
https://trufflesecurity.com - Gitleaks: a lightweight scanner that checks Git repositories for hard-coded secrets. It’s lightweight and easy to run, making it a good fit for small teams or individual developers who want straightforward, reliable detection without extra overhead. https://github.com/gitleaks/gitleaks
- Semgrep – a fast, static analysis tool that scans code in 30+ languages.
https://github.com/semgrep/semgrep?tab=readme-ov-file#option-2-getting-started-from-the-cli - detect-secrets (Yelp): a tool for secret scanning in codebases, designed for enterprise workflows. It creates a baseline of existing findings, then scans diffs with heuristic regex rules to prevent new secrets from being committed.
https://github.com/Yelp/detect-secrets - Distilbert-secret-masker: developed by Anders Andersson. His model is based on a fine-tuned DistilBERT transformer and fine-tuned to detect and classify secrets (API keys, tokens, credentials) in text using Named Entity Recognition (NER).
https://huggingface.co/AndrewAndrewsen/distilbert-secret-masker
Results (Precision, Recall, F1)
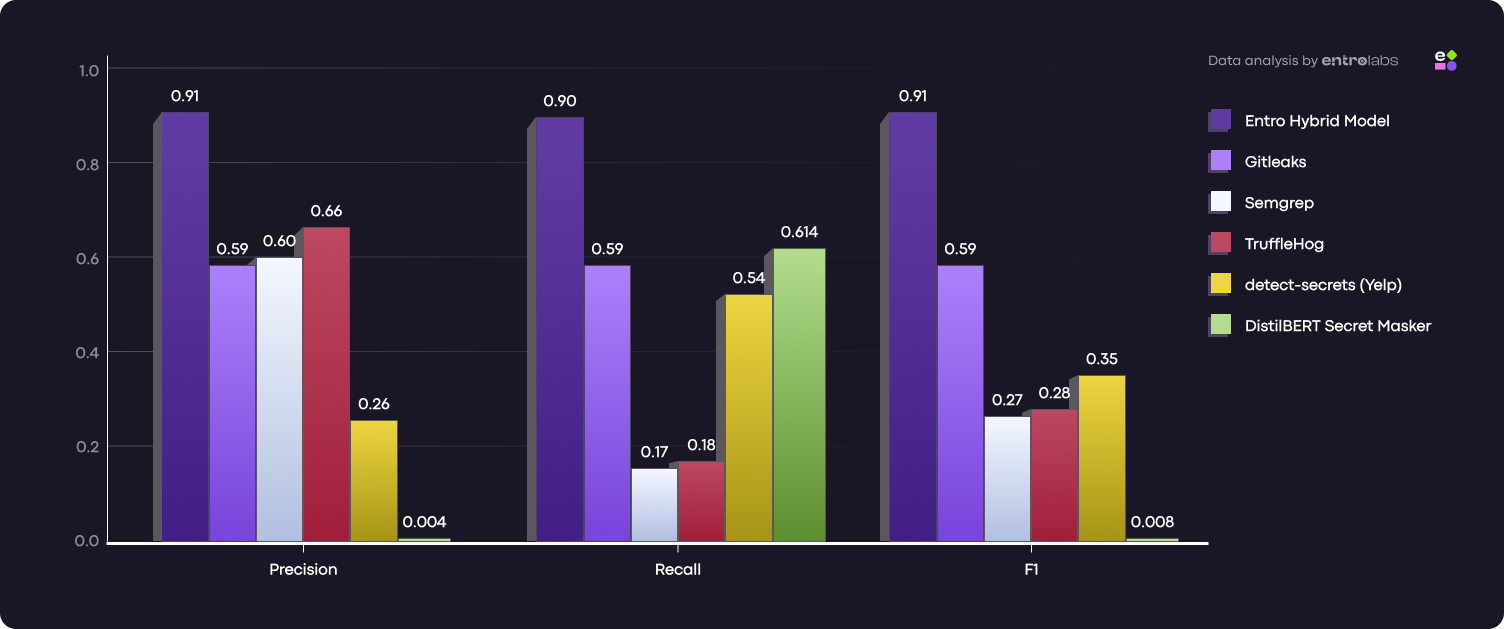
Across the 300-file benchmark, the tools split into clear profiles. Entro’s Hybrid Pipeline is the only one that stays high on both axes: Precision 0.91 (few false positives) and Recall 0.90 (catches most real secrets), yielding F1 0.91.
According to the F1 score, most other scanners ended up choosing a side:
- Cleaner alerts, lower coverage: scanners like TruffleHog and Semgrep tend to be more conservative. They raise fewer false alarms, but they also miss a meaningful portion of real secrets, especially in messy or ambiguous contexts.
- Higher coverage, noisier output: detect-secrets catches more, but does so with more false positives, which increases alert fatigue and makes it harder to trust every finding without validation.
- Middle of the pack: Gitleaks is consistent and practical, but it does not push to the top on either precision or recall. It’s a solid baseline, not the best balance.
- Recall-heavy, precision-light: the DistilBERT-based model tends to flag a lot, but it struggles to stay precise in this setup, which makes the output hard to operationalize without heavy post-filtering.
Entro’s hybrid pipeline stays steady on the hard, ambiguous cases. Generic strings, passwords, and messy real-world context, while still keeping coverage high.
You don’t have to trade trust for detection.
Additional point of reference: a commercial secrets security vendor
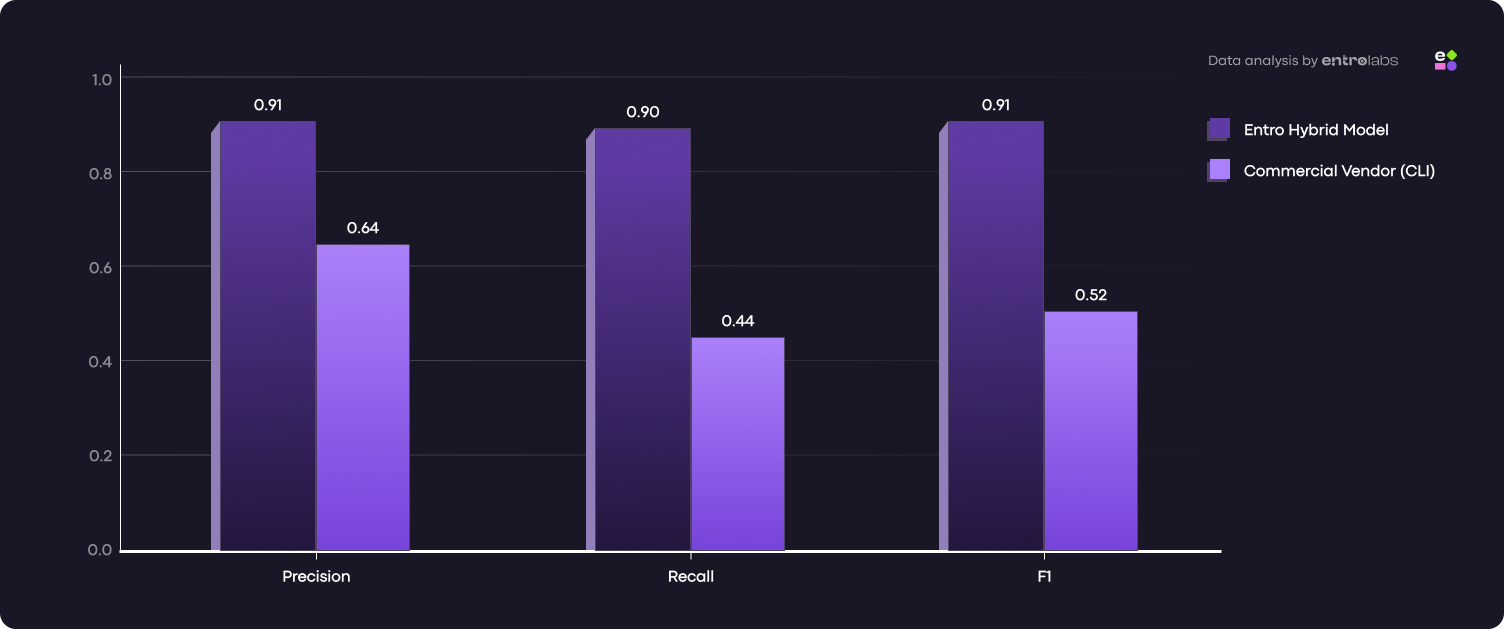
To sanity-check our results, we also ran a popular CLI scanner from a known secrets security vendor on the same 300-file benchmark. In this setup, it behaved like many mature rule-heavy scanners do: decent precision and clean-file handling, but lower recall on real leaks, which pulls down overall F1.
In other words, it was better at staying quiet on clean files than it was at consistently catching secrets across messy, ambiguous, real-world cases. That’s exactly the gap the hybrid pipeline is designed to close, not by swapping one model, but by engineering the full detection pipeline.
Key Takeaway: A Pipeline, Not Just a Model
Building a production-grade Hybrid-based secret scanner isn’t about finding the perfect model/s. It’s about engineering the right pipeline.
- A self-improving loop: by running a rules engine and an SLM side by side, we created a data flywheel. Disagreements between the two don’t just trigger alerts; they become new training data, allowing the pipeline to automatically close gaps and learn from edge cases over time.
- Built for adaptation: the AI ecosystem moves fast. We designed our architecture to be modular. This allowed us to instantly swap and quickly replace SLMs, fine-tune and serve techniques without rebuilding the foundation.
- Data is the product: we didn’t just consume data; we manufactured it. By bootstrapping with rules and filtering with heuristics, we generated the high-signal, production-grade datasets.
Entro built this hybrid pipeline as part of our commitment to customers: keep secret scanning accurate and operational at scale as non-human identities (NHIs) and AI agents proliferate. It’s one example of how Entro is pushing NHI and secrets security forward with production-grade innovation, not just models.